References & Notations
| Item | Instructions |
|---|---|
| ZeRO | ZeRO Redundancy Optimizer |
| ZeRO-Offload | A novel heterogeneous DL training technology designed specifically for large model training |
| M | Model Size |
| B | Batch Size |
| DPU | One-Step Delayed Parameter Update |
| unique optimal offload strategy | 在不增加CPU计算量或者CPU-GPU传输量的前提下,无法节省更多的显存 |
Abstract
大规模训练需要的资源巨大—>ZeRO-Offload
ZeRO-Offload效果:
- 在单张GPU上训练超过13B的参数(相比PyTorch是10倍的提升),不需要修改模型,不会牺牲计算效率。
- 在单张V100上可以训练10B参数,达到40TFlops。与之相比,使用PyTorch最多只能训练1.4B参数,算力也只有30TFlops。
- 支持多GPU,能在128卡下达到接近线性加速。
- 与Model Parallelise结合可以在DGX-2上训练超过70B参数的模型(4.5x提升)。
- 结合了易用性,使得穷人也能训练大模型。
原理:将数据和计算offload到CPU。最小化数据移动,减少CPU计算时间的同时最大化GPU能节省的内存。
Togo: 本文仅探讨了混合精度训练+Adam Optimizer的模型训练。
Introduction
Attention-based DL模型在2017年问世,参数越多,效果越好
| 年份 | 参数量 |
|---|---|
| 2017 | 100M |
| 2018 | 300M(BERT) |
| 2019 | Tens of billions(GPT-2, T5, Megatron-LM, Turing-NLG) |
| 2020 | 175B(GPT-3) |
最新研究表明:想要达到一个比较高的指定精度,训练大模型比训练小模型更高效。
训练大模型的方法:
- Pipeline parallelism
- Model Parallelism
- ZeRO
现有方法的限制:需要Aggregated GPU Memory能hold住整个模型。
例子: 训练一个10B参数量大小的模型,需要16张V100的机器,花费超过100K dollars
ZeRO-Offload的解决办法:用host memory代替显存。
Heterogeneous DL training
之前的异构DL训练工作多关注在CNN based models, 内存瓶颈在activation memory。Model size很小(一般小于500M)。
但是对于最近的Attention based large model training来说,内存瓶颈在Model States, 而不是Activation Memory.
(现有工作的)其他限制:
- 利用了CPU Memory,但是没有利用好CPU Compute(利用好CPU算力主要是为了降低CPU-GPU通信)
- 在单个GPU上设计/评测。对于扩展到集群上没有好的方法。
ZeRO-Offload的优势:
- 利用上了CPU memory和CPU compute
- 扩展到了多GPU。
- 理论上分析: 提供的offload strategy是unique optimal的。
ZeRO-Offload的三个特点:
Efficiency
- 防止CPU计算成为新的瓶颈
- 防止CPU-GPU之间的传输成为新的瓶颈
unique optimal offload strategy
通过分析得出的offload strategy:将gradients, optimizer states, optimizer computation卸载到CPU;GPU上保留parameters, forward and backward computation.
效果:单个V100可以训练13B参数,吞吐量达到40TFLOPS(baseline:单个V100最多训练1.2B参数,吞吐量30TFLOPS)
探讨对CPU造成的额外负担:
- 内存: 服务器内存扩展不成问题
计算: 通过分析,在提供的offload strategy下,CPU的计算量为O(M),GPU的计算量为O(MB)。一般B很大,所以CPU的计算量 << GPU的计算量。当B很小时,CPU就可能成为一个瓶颈,这个时候需要加速/隐藏CPU上的计算
如何加速/隐藏CPU上的计算:
- 加速:实现了一个高效的在CPU上的Adam Optimizer。6x于SOTA IMPLEMENTATION的性能。
- 隐藏:设计了DPU,将CPU计算隐藏于GPU计算中。
Scalability
将offload strategy于ZeRO-数据并行结合。
好处:
- 在CPU Memory上仅维护1个Optimizer states的副本。(传统数据并行有n个worker,就需要维护n个副本)
使聚合的GPU-CPU间通信、CPU计算量为一个常量。(不会随着workers数量增多而增多)。
结果:在128 GPUs上达到了很好的扩展性。并且可以结合模型并行。
Usability
作为PyTorch的一个开源库。几行代码可采用。
Contributions
- Scale Up: unique optimal offload strategy,可以在单个GPU上训练数倍于显存大小的模型。
- Scale Out:
- unique optimal offload strategy + ZeRO powered data parallelism —> 达到接近线性扩展
- 结合模型并行
- CPU计算的优化
- 加速
- 隐藏
- 开源实现
- Extensive Evaluation
Background & Related Work
Memory consumption in large model training
DNN训练中内存消耗大头:
- Model States:parameters, gradients, optimizer states(such as momentum, variances in Adam)
- Residual States: activations, 临时缓冲区, 不可用的碎片内存。
Model States时训练大模型的内存瓶颈主要来源。
分析下各个模型占用的内存大小,考虑混合精度训练,模型中有M个参数:
- Parameters: fp16一份+fp32一份,6M Bytes
- Gradients: fp16, 2M Bytes
- Optimizer States
- momentum: fp32, 4M Bytes
- variance: fp32, 4M Bytes
- Sum up: 16M Bytes
所以总结大模型需要的内存大小如下
| 模型 | 参数量 | 内存占用 |
|---|---|---|
| Megatron-LM | 8 billion | 128GB |
| T5 | 11 billion | 176GB |
| Turing-NLG | 17.2 billion | 284GB |
显卡-显存表
| 显卡 | 最大显存 |
|---|---|
| V100 | 16GB |
| A100 | 80GB |
所以现有显卡单张都不能容纳以上模型。现有工作从以下两个方面来训练大模型:
- scale out
- scale up
Scale out large model training
用多张GPU来训练大模型。
两个经典方式:
- 模型并行
- 流水线并行。
以上两种方式都需要修改user model才能work,限制了usability.
ZeRO提供了另一种方式:将大模型沿着batch维度切分到不同的GPU上,但是并不会像传统数据并行一样在每个GPU上做replicate,而是将model states切分给所有GPUs上,在需要的时候用通信来收集需要的states。
- 好处: 不需要修改模型
- 限制: 仍然需要所有GPUs的聚合显存可以hold住整个模型。
Scale up large model training
在单个GPU上训练更大的模型。
三个典型方式:
- 时间换空间(重复计算换内存占用)
- 压缩model states和activations
- 使用CPU内存作为GPU内存的额外扩展(之前的工作仅offload内存)
ZeRO-Offload采用了第3种方式,并且还offload了部分计算。
ZeRO powered data parallel training.
ZeRO提供了3种层次的策略:
- ZeRO-1: 仅切分optimizer states.
- ZeRO-2:切分optimizer states和gradients(ZeRO-Offload采用这个)
- ZeRO-3:切分所有model states(包括:optimizer states, gradient, parameters.)
ZeRO-2详细介绍:
每个GPU都存储完整的parameters,但是每个GPU只更新其中的一部分(exclusive)。这样,每个GPU只用存储负责更新的parameters部分对应的optimizer states和gradients。在更新parameters后,用all-gather即可完成所有GPU上完整parameters的更新。
流程表示:
- 前向:计算loss
- 反向:计算gradient,使用reduce平均
- 更新:更新自己负责的部分parameters
- 聚合: 使用all-gather更新完整的parameters。
Unique Optimal Offload Strategy
对DL training流程建模,得到一个data-flow graph, 并且根据以下划分原则对图进行划分:
- CPU计算量 << GPU计算量
- 使CPU-GPU传输的计算量最小
- 在保证2的前提下,尽可能的降低显存占用。
本文仅讨论了混合精度训练+Adam Optimizer的情况。
DL Training as a data-flow graph

Limiting CPU Computation
复杂度分析:
- 每次迭代: O(MB)
- 前向/反向复杂度:O(MB)
- norm calculations: O(M)
- weight updates: O(M)
结论:前向/反向不能offload到CPU。
绑定前向和反向为 _FWD-BWD Super Node_,并且必须分配个GPU。
Minimizing Communication Volume
显存带宽 >> CPU memory带宽 >> PCI-E带宽(CPU-GPU, GPU-GPU)
目标: 最小化PIC-E上的通信量,即最小化CPU-GPU之间的通信量。
建模图中的edge最小都是2M,所以,如果将图划分成CPU与GPU两部分,则两部分之间必然最少有两条edges,权重相加最小为4M(理论最小通信量)
达到4M最小通信量的必要条件:
- co-locate所有fp32的节点 —> 将所有fp32节点聚合为一个 _Update Super Node_ —> 建模图中仅剩下4个点: FWD-BWD Super Node, Update Super Node, gradient fp16 Node, parameter fp16 Node.
- parameter fp16 Node必须与FWD-BWD Super Node在同一个设备上(GPU)。
此时仅剩下Update Super Node和gradient fp16 Node尚未决定放在GPU还是CPU上。
Maximize Memory Savings.
穷举Update Super Node与gradient fp16 Node的放置设备。
Update Super Node与gradient fp16 Node均放置在CPU上能达到节省最多的显存。
A unique and optimal offload strategy
略过
ZeRO-Offload Schedule
Single GPU Schedule

反向计算生成的gradient立马(小批量)传送给CPU: 可以隐藏传输开销,并且GPU只需要hold住一小部分缓存的gradient fp16。
Update生成的parameter也类似。

Multi GPUs Schedule( Scaling to Multi-GPUs)

一个GPU对应一个DP(Data Parallel Process):GPU0-N与CPU0之间的聚合通信量是一个与N无关的常量。
GPU之间的通信被转移到了CPU上的reduction。
Model Parallel Training
可以与基于tensor-slicing的模型并行框架协同工作。
Optimized CPU Execution
- 加速:自己在CPU上实现了一个更快的Adam Optimizer
- 隐藏:引入staleness来做overlap。
Implementing the CPU Optimizer
3个优化:
- SIMD vector instruction
- Loop Unrolling
- OMP
Mixed Precision Training wight Adam
略过Optimized Implementation
略过
One-Step Delayed Parameter Update
batch小 —> GPU计算时间(MB)不会远大于CPU计算时间(M) —> CPU计算可能成为一个瓶颈
DPU: staleness换overlap。通过实验验证不会影响最终精度。
DPU Training Schedule

- 前N-1个steps不用DPU:启动阶段梯度变化很大,不适合启用(启用后可能不收敛)
- 第i+1轮训练用的parameters更新自第i-1轮(正常应该是第i轮);第i-1轮的CPU上的参数更新与第i轮的GPU上前向/反向做了overlap。
Accuracy Trade-off
均是一些经验性论述:
- 在训练初始就启用DPu会影响收敛性
- 在若干个steps之后启用DPU不会影响最终精度,并且有更高的吞吐量。
Evaluation
旨在通过Evaluation来论述以下4个问题:
- ZeRO-Offload如何扩大可训练模型的size
- ZeRO-Offload在单个GPU/DGX-2节点上的表现
- ZeRO-Offload在128个GPUs上的表现
- CPU上做的优化的贡献是多少?DPU是否影响模型收敛性?
Evaluation Methodology
Testbed
单个DGX-2:
多个DGX-2:
互联使用648-port Mellanox MLNX-OS CS7500 switch
Workloads
Performance Evaluation
测试的模型: GPT-2 like Transformer based models,通过改变hidden dimension 和Transformer blocks个数来获得不同参数的模型(不能仅仅扩展深度,防止训练变得困难)。
Convergence Analysis
测试的模型:
- GPT-2
- BERT-large (为什么Performance Evaluation种不测试BERT?)
Baseline
比较对象:
- PyTorch DDP:现有的PyTorch Transformer implementation using DistributedDataParallel
- Megatron: 采用模型并行,可以在512GPUs上训练8.3B个参数的模型
- L2L: GPU内存种统一时间仅保存一个Transformer block
- ZeRO: 通过消除GPU间的memory redundancies来增强数据并行。
Experimental Results
Model Scale
测试了在single GPU / single DGX-2 node上能训练的最大的模型的size。
结果: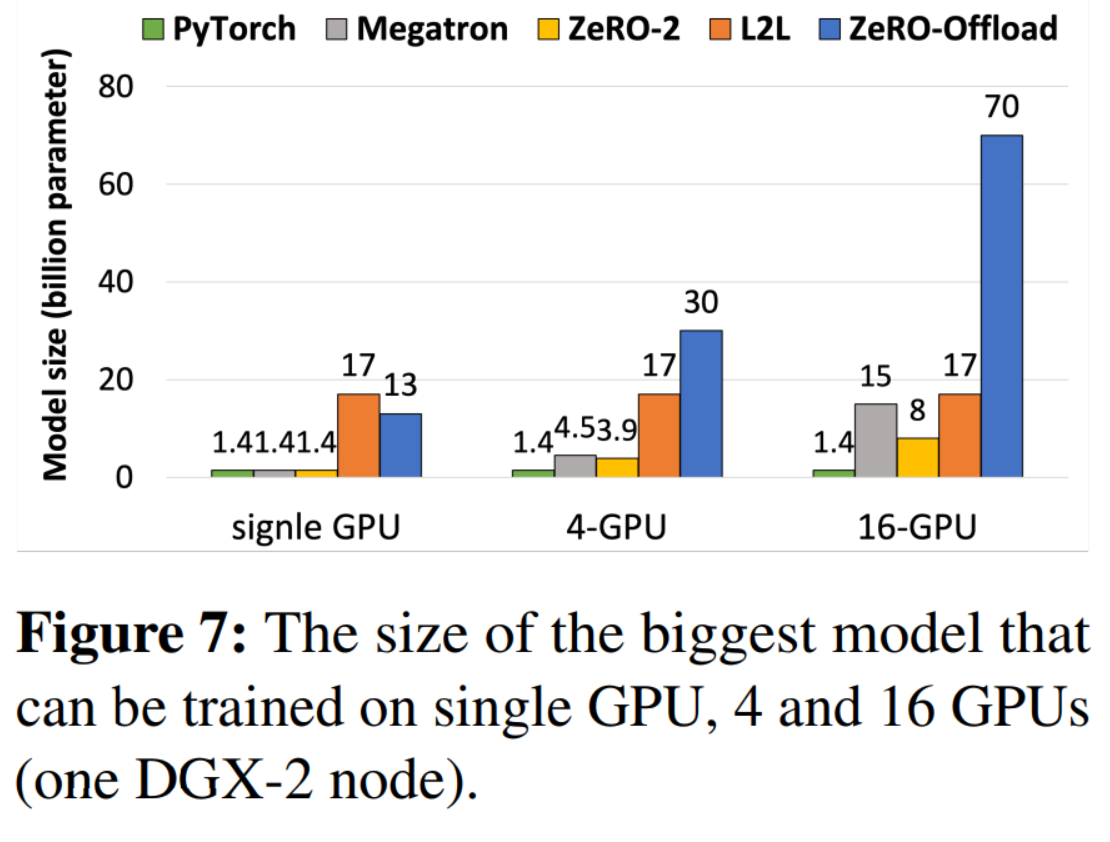
以下为分析:
Single GPU
PyTorch DDP, Megatron, ZeRO-2均为1.4B,因为他们都是利用聚合显存来放置更大的模型。
L2L通过频繁在CPU-GPU间swap weights,成功训练了最大的模型(17B)。但是增加GPU后,L2L的17B不会再增加了。
Multi-GPU in single DGX-2
PyTorch DDP与L2L的可训练最大model size与Single GPU一样:并没有利用好数据并行下的memory redundancies.
Megatron与ZeRO-2可以利用更多的GPU训练更大的模型,但是扩展性不好(最多到15B)。ZeRO-2不好的原因: 没有处理好model weights的冗余。
Training throughput
Single GPU

图中没有Megatron和ZeRO-2的原因:训练超过1.4B大小的模型触发OOM。
本实验中没有开启DPU。
ZeRO-Offload比L2L平均高22%吞吐量,原因:
- 有更低的CPU-GPU通信量:L2L为28M,ZeRO-Offload为4M
- ZeRO-Offload的parameter update在CPU上,经过优化后,相比L2L在GPU上的parameter update仅慢一点(慢多少在Evaluation中有)。
上述原因中第1点加快,第二点减慢,两者结合得到结果:ZeRO-Offload的性能比L2L好一点。
Multi-GPU in single DGX-2

没考虑L2L:L2L的实现没考虑多GPU训练。
实验结果:
- 1B-15B的模型,ZeRO-Offload的性能最高。
- ZeRO-Offload w/o MP能训练的最大模型比ZeRO-2好,因为它offload了optimizer states与大部分gradients到了CPU上。
- ZeRO-Offload w/ MP最大能训练70B参数的模型。Megatron仅利用模型并行,只能训练15B参数的模型(说明ZeRO-Offload的策略很重要)
- ZeRO-Offload比Megatron快的原因:消除了GPU间频繁的通信,可以用更大的micro batch sizes训练;ZeRO-Offload比ZeRO-2快的原因: 用更大的micro batch sizes训练。
Throughput Scalability

结果:
- ZeRO-Offload的聚合吞吐量接近线性。
- ZeRO-2在1-16GPUs上跑不起来
- 32GPUs上ZeRO-Offload通过节省了额外的内存,使得可以用更大的batch sizes做训练,得到相比ZeRO-2更高的性能。
- 在64/128GPUs上,ZeRO-2的性能更好,因为:ZeRO-2没有额外的CPU-GPU间通信。
总结:ZeRO-Offload补足了ZeRO-2。
Optimized CPU execution
CPU-Adam efficiency

- 显著快于PT-CPU
- 与PT-GPU差距不大,不会导致CPU-Adam成为整个训练的瓶颈。
DPU

训练速度更快:1.12-1.59x
Convergence impact
在GPT-2和BERT上做了实验验证(为什么不展示BERT的throughput结果?)。
- GPT组:
- unmodified GPT-2与ZeRO-Offload w/o DPU的loss曲线完全一致:ZeRO-Offload w/o DPU没有对模型做修改。
- ZeRO-Offload w/ DPU在开启DPU后落后一点,后面赶上,随后几乎一致。
- BERT组:
- 大部分都是overlap的,并且收敛趋势一致。
- ZeRO-Offload+DPU的最终训练精度与baseline一致。
结论:
- 经验性的证明DPU不会影响精度。
- 1step的staleness可以忍受。
- DPU不能在一开始就开启。
Conclusions
ZeRO-Offload: a powerful GPU-CPU hybrid DL training technology with high compute efficiency and near linear throughput scalability, that can allow data scientists to train models with multi-billion parameter models even on a single GPU, without requiring any model refactoring.
Open-sourced ZeRO-Offload as part of the DeepSpeed library with the hope to democratize large model training, allowing data scientist everywhere to harness the potential of truly massive DL models.
Questions
- BERT组别为什么展示了精度,不展示吞吐量,这样子看起来很奇怪。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。